
MLOps Project On GCP Using Kubeflow For Model Deployment
Machine learning operations, or MLOps, is the ultimate solution to deploying and managing machine learning models in a production environment. And if the environment is on the Cloud, it allows you to run your Machine Learning pipelines multiple times and track and monitor each run. One such cloud platform is the Google Cloud Platform (GCP). The Kubeflow tool from GCP is perfect for simplifying the deployment of Machine Learning workflows on Kubernetes. But why use Kubeflow for ML model deployment? How to do it? We will guide you through setting up an end-to-end MLOps project on GCP using Kubeflow. So, let’s get started!
Why Use Kubeflow To Deploy Your ML Model?
Kubeflow runs on Kubernetes and supports various services, including Jupyter notebooks, TensorFlow jobs, deployment of TensorFlow models, and end-to-end machine learning pipelines. It has a large community for support and is not limited to TensorFlow; it also supports PyTorch, XGBoost, MXNet, and other tools.
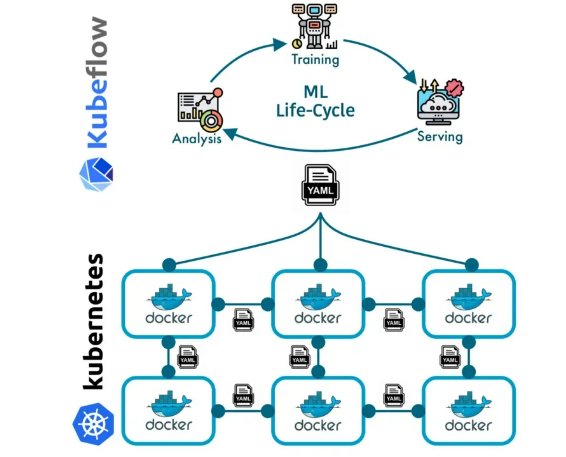
Kubeflow Pipelines is highlighted as a platform for building and deploying scalable machine learning workflows based on Docker containers. Docker images, created from Dockerfiles, serve as blueprints for containers. Kubeflow runs on Kubernetes and utilizes Docker containers for machine learning workflows. Docker images containing machine learning components are orchestrated by Kubernetes, forming an end-to-end workflow.
MLOps Project Prerequisites:
Now, getting straight to the MLOps project on GCP using Kubeflow. You require the following setup to run your MLOps workflows through Kubeflow pipelines:
➢ A GCP account with appropriate permissions.
➢ Google Cloud SDK installed on your local machine.
➢ Basic knowledge of Kubernetes and Docker.
➢ Python is installed on your local machine.
Step 1: Set Up A GCP Project
You must set up a Google Cloud account before building Docker images and machine learning pipelines. You can create a free account and receive $300 in initial credits to create your MLOps project. Follow the below steps to set up your GCP account:
➢ Visit the Google Cloud Platform (GCP) Console and create the GCP account.
➢ Activate $300 in credits to start your free trial.
➢ Verify your location information and agree to the terms of the trial service.
➢ Enter your mobile number and email for 2-factor authentication purposes.
➢ Provide your business information and card details for future payments.
Now you have an active account, create a new project and enable necessary APIs like Cloud Storage API, AI Platform Training & Prediction API, and Kubernetes Engine API. Once you've completed the steps, your account setup is done like the below image.
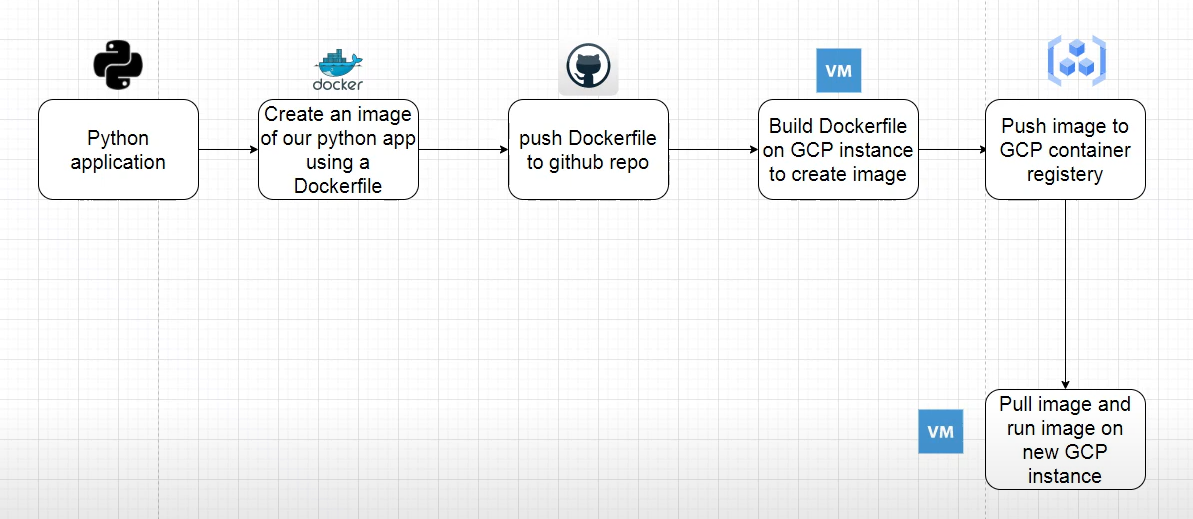
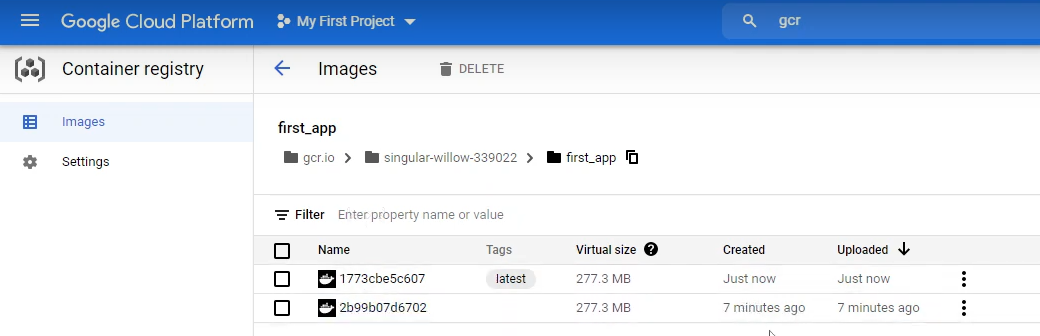
Step 2: Push The Docker Image Of The MLOps Model To GCR
Now, you will create the MLOPs model you plan to deploy and manage through Kubeflow. Take reference from the workflow to better understand what we will be doing in this step!
1. Writing the Python Application: Let's start by writing the Python application using FastAPI. Create a new file named main.py in your project directory and add the following code:
This application will utilize the Iris dataset to generate and display plots based on user requests. This FastAPI application defines an endpoint /iris, which, when accessed, generates a simple plot using the Iris dataset.
2. Creating a Dockerfile: Create a Dockerfile in the same directory as your main.py file. This Dockerfile will be used to build the Docker image for your application:
Make sure to update the requirements.txt file with the necessary dependencies, including fastapi, matplotlib, and any other libraries your application requires.
3. Building and Pushing the Docker Image to Google Container Registry: Build and run the Docker image locally to verify that the application works as expected:

Now, you should be able to access the FastAPI application at http://localhost:8080/iris in your web browser. Thus, follow the previous steps you've learned to push your Docker image to Google Container Registry.
Step 3: Set Up Kubeflow On The GCP Kubernetes cluster
You need to follow quite a few steps to set up Kubeflow on a Google Cloud Platform (GCP) Kubernetes cluster:
1. Prepare the Docker image for your ML pipeline:
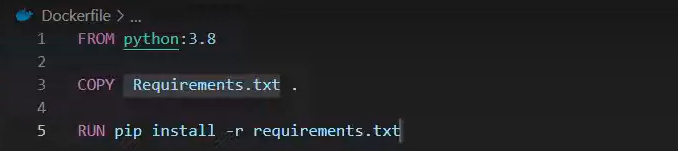
Open Visual Studio Code and create a new file named Dockerfile. Write the Dockerfile with the following content:
Create a new file named requirements.txt and add the necessary Python libraries for your machine learning pipeline:

Now, write the cloudbuild.yaml file as the Cloud Build configuration with the following content:
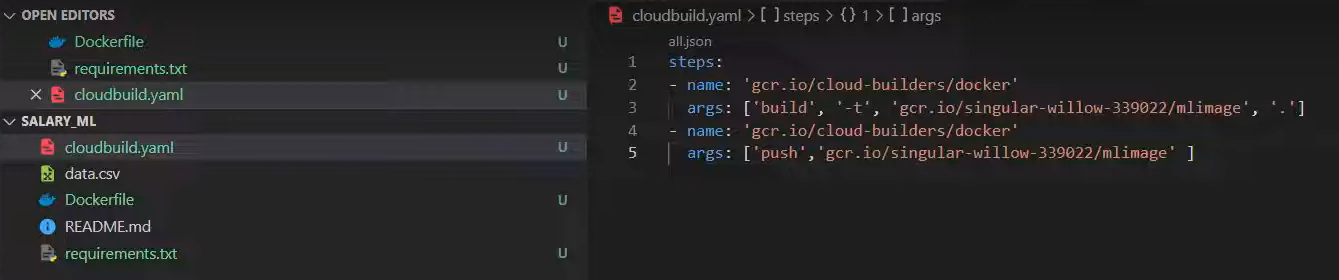
Next, install the Google Cloud SDK (gcloud) on your local machine. Run "gcloud init" command to authenticate and set up the default configuration. Finally, run the following command to build and push the Docker image:
gcloud builds submit --config=cloudbuild.yaml .
Now the Docker Image is ready; we will continue the Kubernetes cluster setup with Kubeflow.
2. Set Up The Kubernetes Cluster
Go to the GCP Console to navigate to the Kubernetes Engine and find the option to create clusters like the ones below.
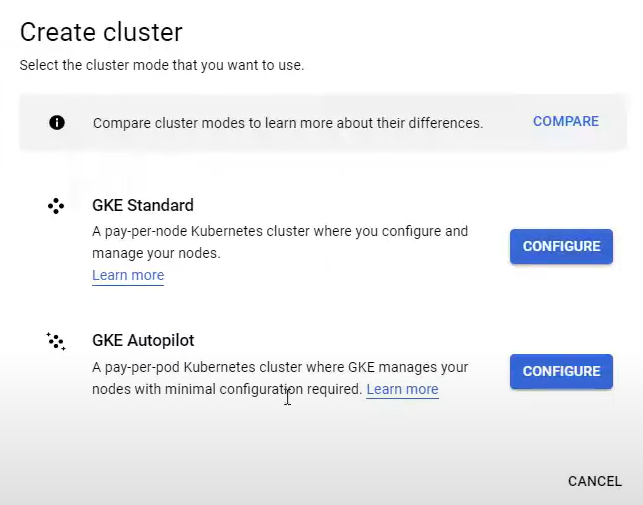
Click "Create Cluster" and choose GKE Standard. Specify cluster details (name, zone, node pool configuration). Allow full access to all Cloud APIs in the Security section. Wait for the Cluster creation to complete and check the deployment status to confirm.

3. Set Up The Kubeflow Pipeline
Go to the GCP Console to find the option for “AI Platform” and click on “Pipelines” as below:
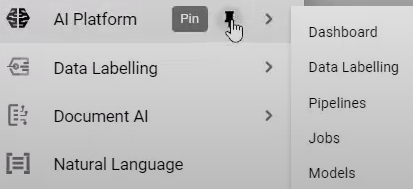
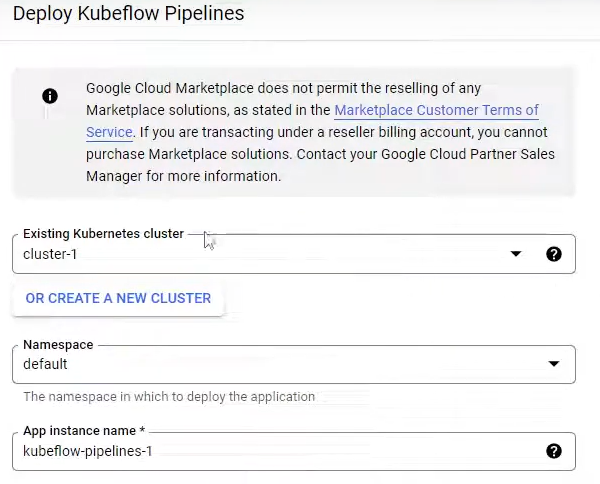
Create a new AI Platform Pipelines instance. You can configure it with the existing Kubernetes cluster. Accept default values and click "Deploy."
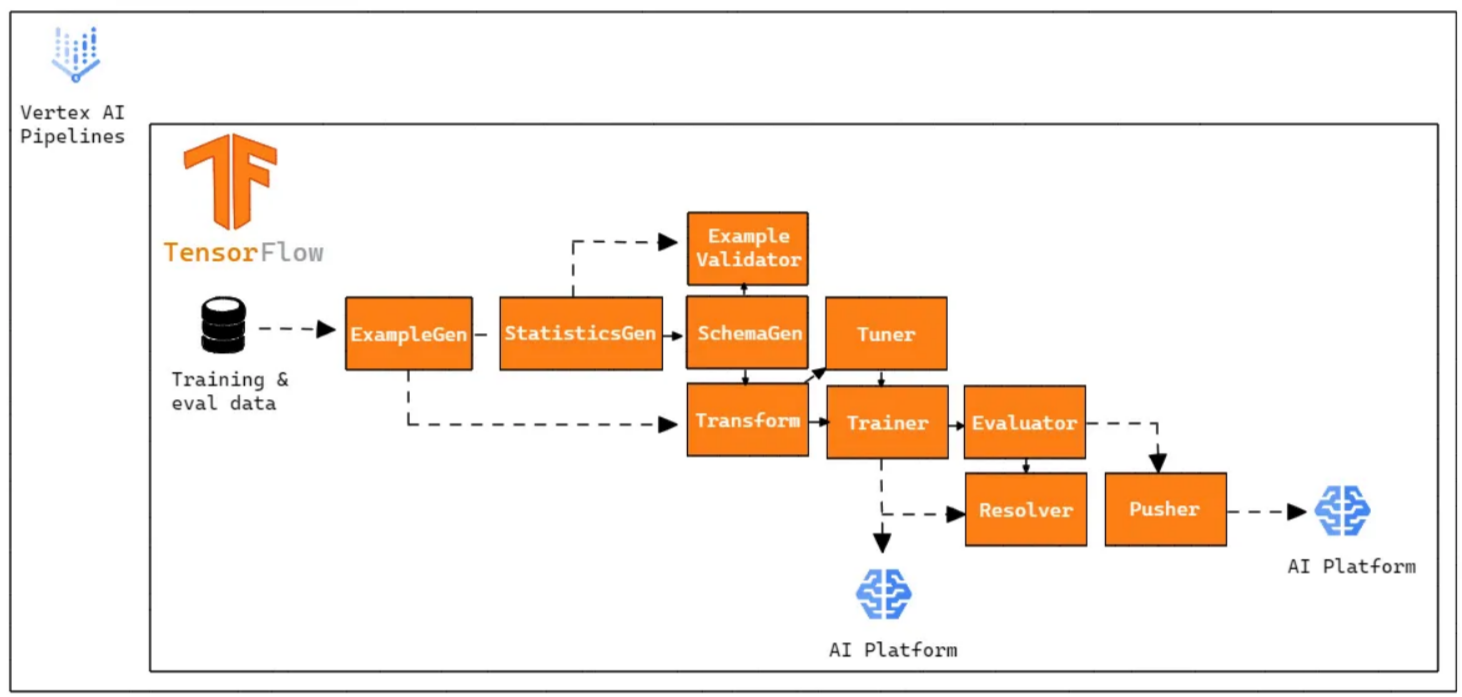
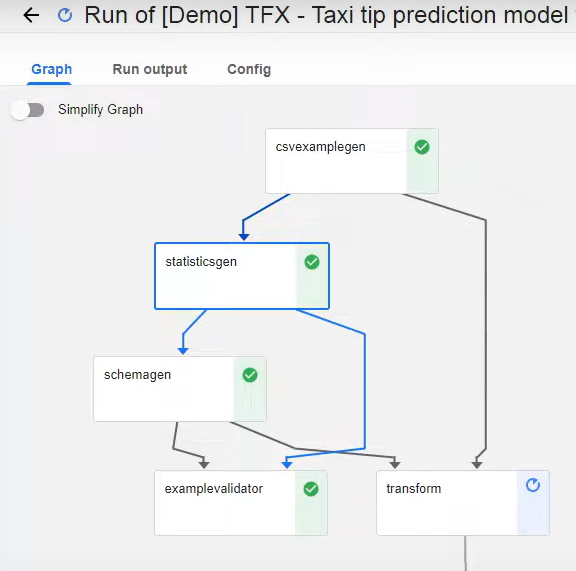
Open the Kubeflow Pipelines Dashboard from the AI Platform. Explore the newly created pipelines interface. There, you will find other pre-built pipeline examples and experiments. Understand the structure of a sample TFX (TensorFlow Extended) pipeline given below. Trigger a run by creating a new run instance. Monitor the run's progress and inspect components like inputs, outputs, and logs.
There you have it! You have successfully covered setting up your Kubeflow pipeline and running the MLOPs model. In the coming section, we will review how to orchestrate the TFX pipeline components in the cloud using Kubeflow.
Step 4: Set Up The TFX Pipeline With Kubeflow
You can set up the machine learning pipeline on Google Cloud using TensorFlow Extended (TFX) and Kubeflow. The specific focus is on the data ingestion component using TFX ExampleGen.
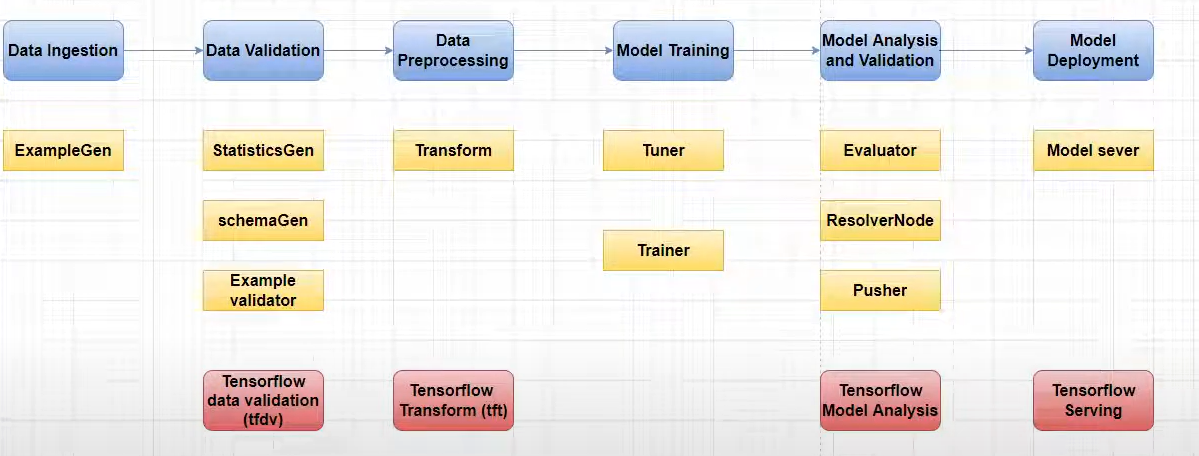
The steps include:
➢ Create a cloud storage bucket to store pipeline-related folders and files.
➢ Create folders within the bucket for metadata, data, and models.
➢ Upload U.S. census data to the data folder in the cloud.
➢ Write Python code in Visual Studio Code to define the pipeline components, primarily focusing on the model component for data splitting (training and validation).
➢ Run the pipeline on Kubeflow using a Kubeflow Runner.
➢ Handle errors related to Windows environment variables (specifically "home").
➢ Resolve authentication issues by creating and setting a Google Cloud service account key.
➢ Rerun the pipeline and upload it to the Kubeflow dashboard.
Thus, you now have a clear and comprehensive overview of the process involved in creating and running a Machine Learning pipeline on the Google Cloud.
Let’s Wrap Up!
Congratulations! You've successfully set up an MLOps project on GCP using Kubeflow for model deployment. This comprehensive guide should help you understand how to set up your GCP account and build your Kubeflow pipelines on the Kubernetes cluster.
CTA: Continue your MLOps & GCP learning journey with us!


